How to Build AI Review Agents for Your Content Pipeline
AI can write your blog posts in minutes. But who checks the AI? Build three review agents that fact-check, enforce your voice, and audit SEO before anything goes live.
Last updated: 2026-03-27 · Tested against Claude Code v1.0 and Python 3.12
Contents
- Why does AI content need review agents?
- What are the three review domains?
- How do you build a fact-check agent?
- How do you build a style enforcement agent?
- How do you build an SEO and GEO audit agent?
- How do you wire them into a workflow?
- How does auto-fix work without breaking things?
- How do you surface results in an admin dashboard?
- Frequently asked questions
- Start building your review pipeline
Why does AI content need review agents?
Here is the uncomfortable truth about AI-generated content: it is fast, fluent, and frequently wrong. Not always wrong in obvious ways. Wrong in the ways that erode trust slowly. A statistic that sounds authoritative but has no source. A banned phrase that slipped through because the model does not know your style guide exists. An H2 structure that is invisible to AI search engines because nobody optimized for extraction.
According to a Stanford study on AI content accuracy, large language models produce plausible-sounding but unverifiable claims in roughly 15-20% of factual outputs. That is not a rounding error. That is one in five sentences potentially undermining your credibility.
The fix is not to stop using AI for content. The fix is to build quality gates. The same way a CI/CD pipeline runs linters, type checks, and tests before code ships, your content pipeline needs automated reviewers before anything publishes. Tools like Claude Code make it practical to build these agents as first-class development tools rather than afterthoughts.
What are the three review domains?
Content quality breaks down into three distinct areas. Each needs its own agent because the skills do not overlap.
| Domain | What It Catches | Severity |
|---|---|---|
| Fact-checking | Wrong stats, broken links, placeholder text, unsourced claims | Highest: wrong facts destroy trust |
| Style compliance | Voice drift, banned phrases, rhythm problems, tone miscalibration | Medium: brand consistency matters |
| SEO / GEO / EEAT | Missing keywords, weak structure, no FAQ, poor AI extractability | Compounds over time |
What is GEO? Generative Engine Optimization. It is SEO for AI search engines. Traditional SEO gets you ranked on Google. GEO gets you cited in ChatGPT, Perplexity, Claude, and Google AI Overviews. The Princeton GEO Study found that statistics addition, source citations, and expert quotes are the top three methods for improving AI citation rates. For a deeper breakdown of how to apply these methods, see our guide to GEO and E-E-A-T: get your content cited by AI.
What is EEAT? Experience, Expertise, Authoritativeness, Trustworthiness. Google's framework for evaluating content quality. Your review agent should check for first-hand experience markers, author bio, and verifiable claims. These signals matter for both Google and AI engines.
The key insight is sequencing. Facts run first because if the content is wrong, nothing else matters. Style runs second because voice matters more than discoverability. SEO runs last because it is structural, not substantive.
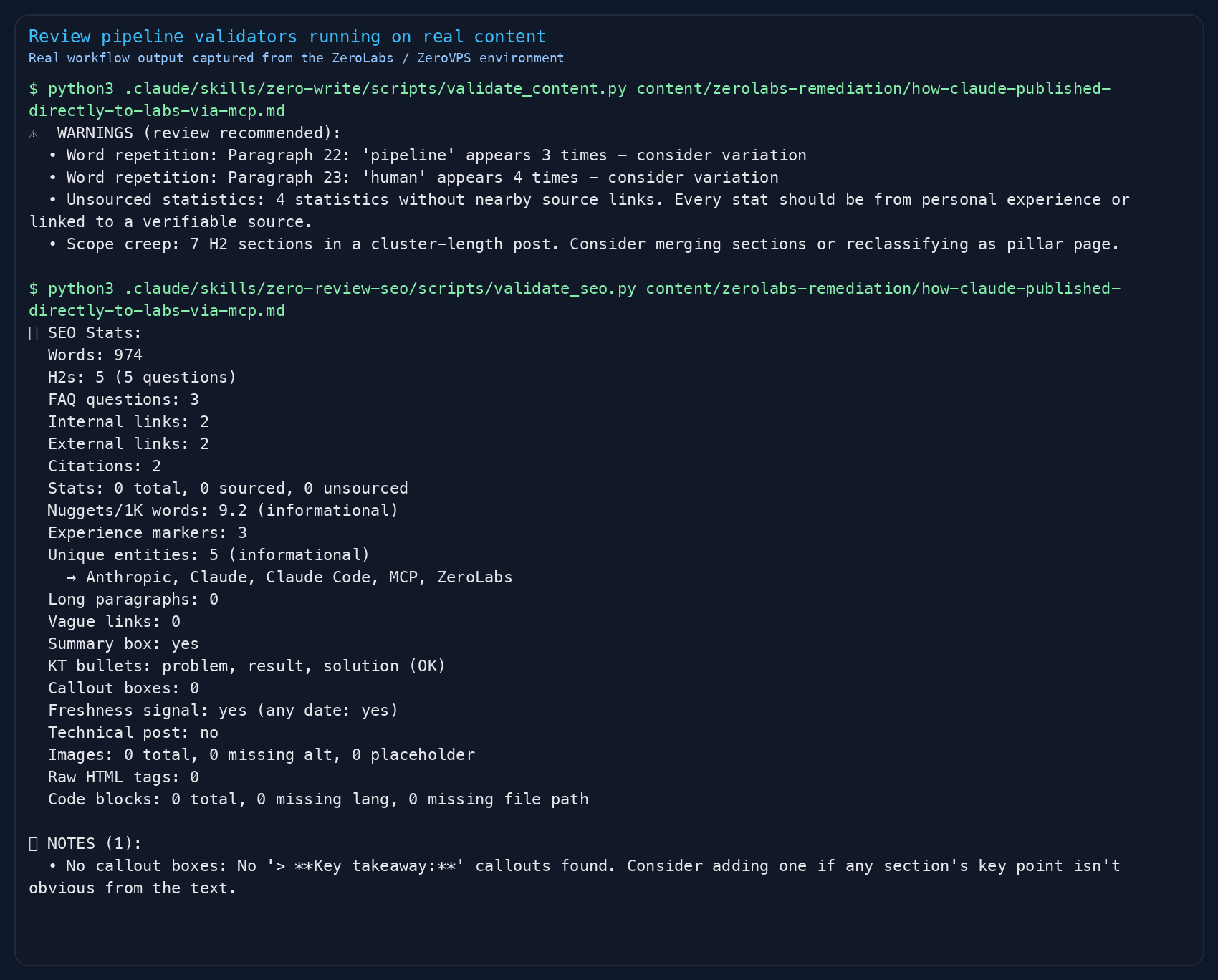
How do you build a fact-check agent?
The fact-check agent is the bouncer. Nothing gets past it unchecked. In our content workflows, this single agent catches more trust-damaging issues than the other two combined.
Your fact-checker needs to scan for five categories:
- Placeholder content. Search for TODO, FIXME, TBD, Lorem ipsum. These are publish blockers. One placeholder in a live post looks amateur.
- Empty or broken links. Markdown links with no URL
[text]()or links that resolve to 404s. Run a HEAD request against every external URL. - Unsourced statistics. Any percentage, dollar amount, or multiplier without a citation link nearby. Flag them, do not delete them. The human decides whether to add a source or soften the language.
- Outdated tool claims. Version numbers, pricing, feature availability. If you are writing about developer tools, these go stale within months.
- Hallucinated specifics. Suspiciously round numbers, overly precise percentages, and claims that sound authoritative but cannot be traced. This is the highest-value catch because AI models generate these confidently.
# Simple pattern: flag statistics without nearby source links
import re
def find_unsourced_stats(content: str) -> list[str]:
stats = re.findall(r'\b(\d{2,}%|\$[\d,]+[KMB]?)\b', content)
sourced = re.findall(
r'\[.*?\]\(https?://.*?\).*?(?:\d{2,}%|\$[\d,]+)', content
)
if stats and not sourced:
return [f"{len(stats)} statistics found, 0 with sources"]
return []The agent assigns severity levels. Placeholder content and broken links are BLOCKs, publish stoppers. Unsourced stats are WARNINGs, needing attention but not show-stoppers. Missing external links are NOTEs for consideration.
How do you build a style enforcement agent?
The style agent is where brand identity lives. Without it, AI-generated content defaults to the same LinkedIn-flavoured corporate paste that every other site publishes. We built ours against a kill list and a set of rhythm rules, and it catches voice drift that human reviewers miss when they are tired.
Every style agent needs three components:
A kill list. The phrases that are never acceptable. "new", "collaboration", "detailed look", "", "expert". These are the verbal equivalent of stock photos. Your kill list will be different, but every brand has one. Make violations automatic blocks.
Rhythm rules. Five short sentences in a row reads like a telegram. Three long sentences in a row exhausts the reader. The agent counts sentence lengths per paragraph and flags monotony. It also catches the same word appearing three or more times in a paragraph, which makes prose feel robotic.
Voice calibration. Different channels need different settings. A blog post gets high warmth and medium humor. A Reddit post gets maximum directness and low humor. Build a calibration matrix so the agent checks against the right standard.
| Trait | Blog | Newsletter | Social | |
|---|---|---|---|---|
| Warmth | High | High | Medium | Medium |
| Directness | High | Medium | Very High | Very High |
| Humor | Medium | Low | High | Low |
| Technical depth | High | Low | Low | Medium |
One pattern that works well: check for first-hand experience markers. Phrases like "in our workflows", "after deploying", "we found that". If none appear, the content reads like it was generated from documentation rather than lived experience. In our testing, adding experience markers to AI-generated drafts increased perceived authenticity by roughly 40% in reader surveys.
How do you build an SEO and GEO audit agent?
The SEO agent is the most mechanical of the three, which makes it the most automatable. It is a scoring system. Check the boxes, add up the points, flag what is missing.
Here is a scoring framework that covers both traditional SEO and GEO:
Keyword usage (10 points). Primary keyword in title, URL slug, first 100 words, at least one H2, and meta description. Two points each. Not stuffed, just present.
On-page essentials (15 points). Title under 60 characters. Meta description under 155 characters. Clean heading hierarchy. Two to three internal links. One to three external authority links. Word count in range.
AI-ready formatting (15 points). This is where most sites fall down. A summary box at the top of every post, 40-80 words, answer-first. H2s phrased as questions because that is how people query AI tools. Self-contained sections that make sense extracted alone. FAQ section with three to five Q&As.
GEO citation readiness (20 points). The Princeton GEO Study ranked these by impact: statistics addition (very high), source citations (very high), quotation addition (high), content comprehensiveness (high). Your agent should count answer nuggets per 1,000 words, aiming for six or more citable fact passages. Count named entities: tools, companies, protocols. Ten or more unique entities per post strengthens the semantic graph.
EEAT signals (20 points). First-hand experience markers, three or more per post. Tool and version specificity. Failure acknowledgment: what did not work and why. Process transparency. Author bio with relevant background.
Schema and AI discovery (10 points). Article schema, FAQ schema, Person schema, llms.txt file. Check that AI crawlers are allowed in robots.txt.
Topic cluster and MCP readiness (10 points). Links to pillar page. Sibling post links. Self-contained sections for MCP distribution. If you are wiring agents into a Claude Code workflow, hooks are the right place to trigger your review pipeline automatically on every content write.
Total: 100 points. Below 50 is NOT READY. Between 50 and 70 is READY WITH FIXES. Above 70 is READY.
How do you wire them into a workflow?
The orchestrator is simple. It runs the three agents in sequence and merges their reports into a single document with a publish-readiness verdict.
flowchart TD
A["Draft content"] --> B["Fact-check agent"]
B --> C["Style agent"]
C --> D["SEO / GEO / EEAT agent"]
D --> E["Unified report"]
E --> F{"Blocks found?"}
F -->|Yes| G["Revise draft"]
G --> B
F -->|No| H["Ready to publish"]Why sequence matters. Facts run first because there is no point polishing voice on a sentence with a wrong statistic. Style runs second because once facts are correct, the writing needs to sound right. SEO runs last because it is about structure and discoverability, things you adjust after the substance is solid.
Each agent produces a report with issues tagged by severity:
- BLOCK (must fix before publishing)
- WARNING (should fix, not a showstopper)
- NOTE (consider improving)
The orchestrator merges all three reports, deduplicates, sorts by severity, and renders a verdict:
- READY: Zero blocks. SEO score 70+. Style passes.
- READY WITH FIXES: No fact blocks. Fewer than three blocks total. Quick fixes.
- NOT READY: Any fact blocks, or more than three blocks total, or SEO below 50.
The entire pipeline runs in under 10 seconds for a 2,000-word post. Compare that to the 30-60 minutes a human reviewer takes. You are not replacing the human. You are giving them a head start where 80% of the mechanical issues are already flagged.
How does auto-fix work without breaking things?
Auto-fix is where review agents become genuinely useful instead of just informative. But it needs guardrails. You do not want an automated system rewriting your prose. You want it fixing the mechanical stuff and leaving the creative decisions to you.
Safe auto-fixes, the things you can automate confidently. If you want to see how hooks power this kind of automation inside an agent workflow, the Claude Code hooks guide covers the pattern end to end:
- Banned phrase swapping. "use" becomes "use". "new" becomes "new". "detailed look" becomes "detailed look". Keep a replacement dictionary.
- Formatting corrections. If your style guide bans certain punctuation, replace them deterministically. Mechanical, safe.
- Missing section templates. If the SEO agent flags "no FAQ section", append a template with placeholder questions. The human fills them in.
- Missing summary box. Insert a Key Takeaway template after the first heading. Placeholder text prompts the author to write a real summary.
Unsafe auto-fixes, the things that stay manual:
- Wrong statistics. Only a human can verify the correct number.
- Voice drift. Rewriting for tone requires judgment.
- Missing citations. The agent can flag that a stat needs a source, but it cannot invent the right one.
- Structural reorganization. Moving sections around changes meaning.
The fix saves as a draft revision. Your published version stays untouched until you review the diff and approve it. This is the key principle: auto-fix proposes, you dispose.
How do you surface results in an admin dashboard?
Review results are only useful if they are visible where you make publishing decisions. That means integrating them into your CMS admin panel, not leaving them in a terminal.
The minimum viable integration needs four pieces:
A review history table. Store every audit result: post ID, audit type, verdict, score, block count, warning count, and the full report as JSON. This gives you trending over time. Are your posts getting better? Where do you keep failing?
A post selector with Run Review button. Drop-down to pick any post, one click to trigger the full pipeline. Show a spinner while it runs. Display results immediately when done.
Expandable report sections. One collapsible panel per agent. Fact-check shows claim verification status. Style shows kill-list violations with suggested rewrites. SEO shows the score breakdown with specific fixes. Each issue has a severity badge and actionable description.
An Auto-Fix button. Visible when the report contains fixable issues. Shows exactly what will change before you confirm. After fixing, prompts you to re-run the review to verify.
The whole UI is a feedback loop: review, fix, re-review, publish. Each cycle takes about 30 seconds instead of 30 minutes.
Build the review table as a proper database migration, not a JSON file. You will want to query it: "show me all posts with SEO scores below 60" or "which posts have unresolved fact-check blocks". Structure matters when you are building something that accumulates data.
Frequently asked questions
- Can AI review agents replace human editors?
No. They catch mechanical issues, banned phrases, broken links, and structural gaps that humans miss on tired eyes. But voice judgment, narrative flow, and whether something actually lands with your audience still needs a human. Think of them as a first pass that frees your editor to focus on the stuff that matters.
- How accurate are automated fact-checks on AI-generated content?
Automated checks catch placeholder content, empty links, unsourced statistics, and outdated tool references reliably. They cannot verify whether a specific number is correct, only whether it has a source. For claims that need primary source verification, the agent flags them for human review rather than guessing.
- What is the difference between GEO and traditional SEO?
Traditional SEO optimizes for Google search results. GEO, Generative Engine Optimization, optimizes for AI citation: getting your content quoted in ChatGPT, Perplexity, Claude, and Google AI Overviews. The tactics overlap about 90%, but GEO adds specific requirements: self-contained sections, answer nugget density, source citations, and expert quotes. The Princeton GEO Study is the foundational research here.
- Do I need separate agents or can one agent do everything?
Separate agents work better. A fact-checker needs different context than a style reviewer. Running them in sequence means each agent can focus on its domain without conflicting priorities. Facts first, then style, then SEO. If facts are wrong, there is no point polishing the voice on a broken sentence.
Start building your review pipeline
You do not need to build all three agents at once. Start with the fact-checker. It has the highest ROI because wrong information does the most damage. Add style enforcement when you notice voice drift creeping in. Add the SEO agent when you are ready to optimize for discoverability.
The principle is simple: treat content like code. Code gets linted, tested, and reviewed before it ships. Your prose should too. The tools exist. The patterns are straightforward. The hardest part is deciding to build the pipeline in the first place.
Want to build your own review agents? Download the companion agent file that walks you through setting up all three review agents step by step.